第3章 AI RAG技術の概要
3.1 生成AIの基本構造
生成AIとは、大規模なデータを学習した言語モデルを用いて、人間の自然言語に近い文章を生成する技術である。近年では大規模言語モデル(Large Language Models:LLM)の発展により、質問応答、要約、翻訳など、多様なタスクにおいて高い性能を示している。
生成AIは、入力されたテキスト(プロンプト)に基づき、学習時に獲得した統計的な言語パターンを用いて、次に続く語や文を予測・生成する仕組みを持つ。このため、自然な文章生成能力に優れる一方で、学習データに含まれない情報や、企業固有のルール、最新の法令改正といった情報を正確に反映することが困難であるという特性を有している。
特に企業内業務においては、生成AIが「もっともらしいが誤った回答」を生成する可能性がある点が課題として指摘されており、正確性や説明責任が求められる領域では慎重な利用が必要とされている。
3.2 RAG(Retrieval-Augmented Generation)の仕組み
RAG(Retrieval-Augmented Generation)は、生成AIに検索機能を組み合わせることで、外部または内部の知識を参照しながら回答を生成するアーキテクチャである。RAGは、従来の生成AIが抱えていた「学習データに依存する」「根拠を示せない」といった課題を補完する技術として注目されている。
RAGの基本的な構造は、質問理解 → 情報検索 → 回答生成という三層構造で整理できる。
この全体像を示したものが 図2である。
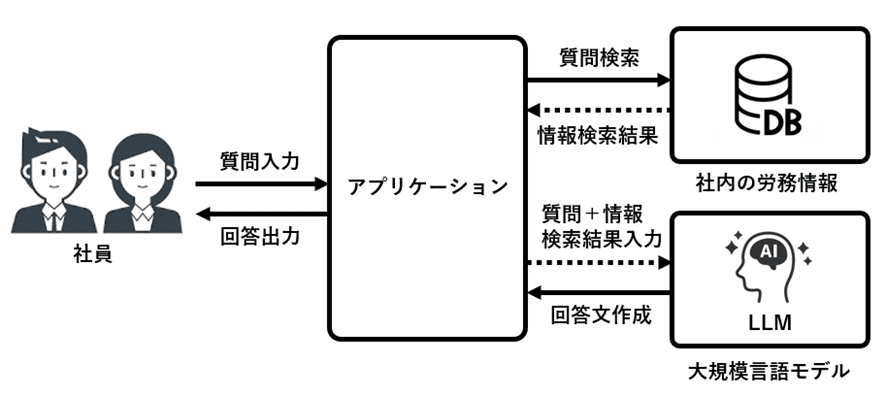
図2に示すように、RAGは主に以下の要素から構成される。
第一に、ユーザー入力(質問)である。利用者は自然文で質問を行い、専門的な検索語や制度名称を正確に把握している必要はない。
第二に、検索(Retrieval)コンポーネントである。ここでは、社内規程、マニュアル、FAQ、法令資料、過去の問い合わせ履歴など、あらかじめ登録されたナレッジベースから、質問内容と意味的に関連性の高い情報が抽出される。この検索は、単純なキーワード一致ではなく、文脈や意味的類似性を考慮した方法で行われる点に特徴がある。
第三に、生成AI(LLM)である。検索によって取得された情報は、生成AIの入力として与えられ、回答の根拠として利用される。生成AIは、新たな知識を創出するのではなく、取得した情報を整理・要約し、利用者にとって理解しやすい形で回答を生成する。
第四に、回答および根拠提示である。RAGでは、生成された回答とともに、参照した文書や該当箇所を明示することが可能であり、回答の妥当性や説明可能性を確保できる。
RAGの特徴的な点
このような構造により、RAGは以下の特徴を有する。
- 企業固有のナレッジを動的に参照できる
- 最新の法令・規程情報を反映できる
- 回答の根拠を提示できるため、説明責任を果たしやすい
特に、正確性と再現性が求められる企業内業務においては、RAGは生成AI単体よりも実務適用性が高いと評価できる。
労務業務との接続
労務業務においては、回答そのものよりも「なぜその回答になるのか」という根拠が重要視される。RAGの概念図が示すように、検索と生成を明確に分離し、参照情報を可視化できる点は、労務領域におけるAI活用の前提条件を満たすものである。
次節では、従来型の生成AIとRAGの違いを整理し、なぜRAGが企業内業務、とりわけ労務業務に適しているのかを比較の観点から検討する。
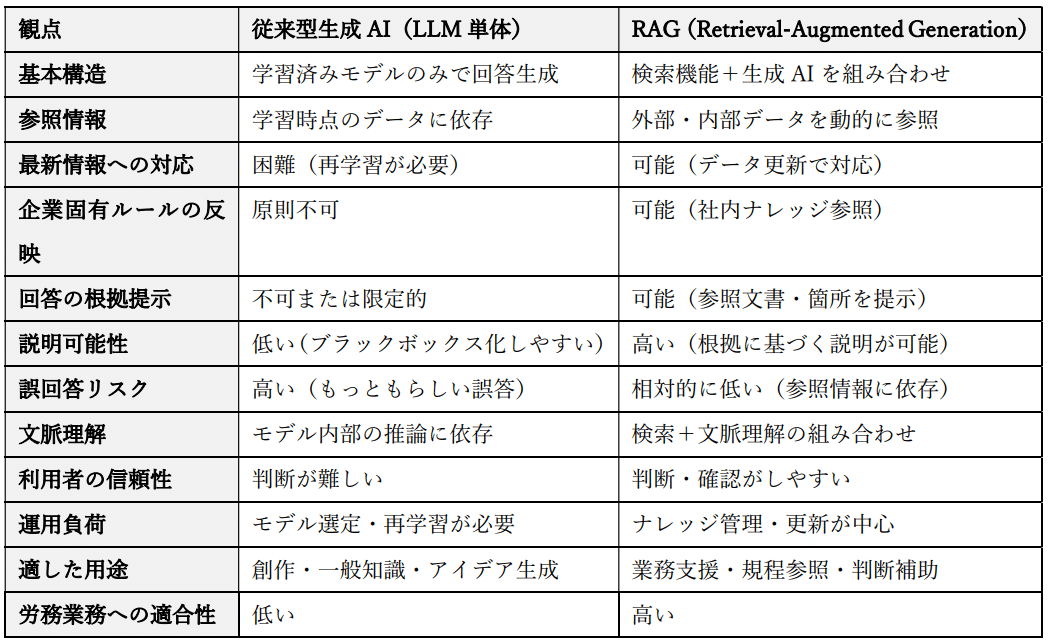
3.3 従来型生成AIとRAGの違い
従来型の生成AIは、あらかじめ学習された知識に基づいて回答を生成するため、企業固有の文脈や最新の情報を正確に反映することが難しい。一方、RAGは検索機能を通じて外部知識を動的に参照する点に特徴がある。
この違いは、企業内業務において極めて重要である。特に労務業務では、法令や社内規程といった「正解の根拠」が明確に存在するため、回答の妥当性を説明できない生成AIは実務適用が困難である。RAGは、回答に用いた文書や条文を明示できる点で、従来型生成AIに比べて高い説明可能性を有している。
3.4 RAGにおける「検索」「根拠提示」「回答生成」のプロセス
RAGの処理プロセスは、大きく「検索」「根拠提示」「回答生成」の三段階に整理できる。
第一に、ユーザーの質問を解析し、関連性の高い文書やデータを検索する。この際、単純なキーワード検索ではなく、文脈や意味的類似性を考慮した検索が行われる。
第二に、検索によって取得された情報の中から、回答の根拠となる部分が抽出・整理される。この段階では、どの文書のどの部分が参照されたのかを明示することが可能であり、回答の信頼性を担保する役割を果たす。
第三に、抽出された根拠情報を基に、生成AIが自然言語による回答を生成する。ここで重要なのは、RAGが「新たな判断を創出する」のではなく、「既存の情報を整理し、理解しやすい形で提示する」点にある。
3.5 企業内業務におけるRAGの優位性
企業内業務においてRAGが有する最大の優位性は、組織固有の知識を活用しながら、回答の正確性と説明可能性を両立できる点にある。
従来の検索型システムでは、利用者が情報を解釈し、判断する必要があった。一方、RAGは検索結果を単に提示するのではなく、複数の情報を統合し、文脈に即した形で提示することができる。この特性は、知識が分散し、属人化しやすい管理部門業務との親和性が高い。
また、RAGは元となるナレッジを更新することで回答内容が自動的に変化するため、法改正やルール変更への追随が容易である。この点は、更新負荷が高い従来型FAQとの大きな違いである。
3.6 労務領域における適用可能性
労務業務は、正確性、再現性、説明責任が強く求められる領域であり、生成AIの安易な適用はリスクを伴う。しかし、RAGを用いることで、社内規程や法令を根拠として提示しながら情報提供を行うことが可能となり、労務業務との適合性が高まる。
特に、社員からの問い合わせ対応においては、RAGを活用することで反復的な質問への対応を効率化しつつ、労務担当者は判断が必要な高度案件に集中することが可能となる。また、上司や社労士に確認した知見をナレッジとして蓄積・再利用することで、組織としての対応力を高めることが期待される。
以上のことから、RAGは労務業務を単に自動化する技術ではなく、判断を支援し、知識を組織化する基盤技術として位置づけることができる。次章では、この特性を踏まえ、労務業務に特化したRAG活用モデルについて検討する。