― 精度が出る会社と出ない会社の決定的な違い ―
近年、労務業務にAI RAG(Retrieval-Augmented Generation)を活用する企業が増えています。
しかし、「RAGを入れたが思ったほど精度が出ない」「結局、労務担当者への問い合わせが減らない」という声も少なくありません。
その原因の多くは、AIモデルではなく「データセットの作り方」にあります。
本記事では、労務RAGの研究·実務検証を通じて見えてきた、精度が出る労務データセットの作成方法を分かりやすく解説します。
1. 労務RAGは「データが9割」
まず大前提として理解すべき点は、労務RAGは「賢いAIを入れれば解決する仕組み」ではないということです。
労務RAGの回答品質は、以下でほぼ決まります。
- どんなデータを
- どの形式で
- どの順番で
- どこまで更新管理しているか
つまり、労務RAGはデータ設計の良し悪しがそのまま精度に直結する仕組みです。
2. まず考えるべきは「用途」と「目的」
労務データセット作成で最初にやるべきことは、
いきなり資料を集めることではありません。
① 用途(誰が使うか)
労務RAGの利用者は、大きく次の3種類に分かれます。
- 社員からの問い合わせ
- 管理職からの問い合わせ
- 労務担当者からの問い合わせ
この3者は、求める答えの粒度がまったく異なります。
② 目的(何のために使うか)
目的も2つに分けて考える必要があります。
- 参照書類を明示して「回答案」を作る
- 判断を支援する(論点整理·材料提示)
この「用途 × 目的」を整理しないままデータを作ると、
RAGは「それっぽいが使えない回答」を量産します。
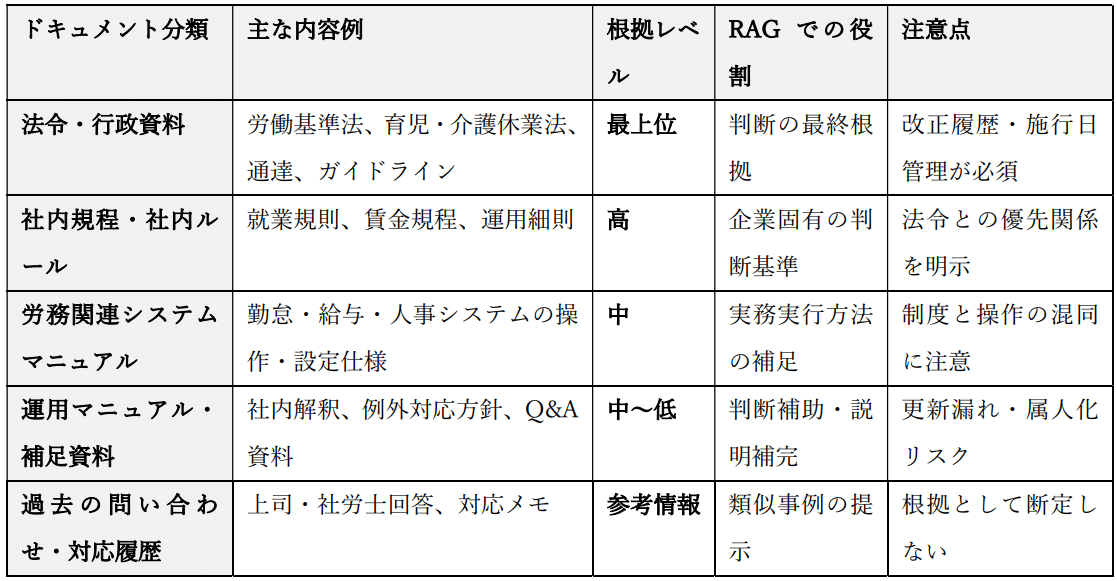
3. 労務RAGに必須のデータセット分類
実務検証の結果、労務RAGで精度が出やすいデータは以下の順です。
① Q&Aデータ(最優先)
- 社員·管理職·労務担当者から実際に出た質問
- 過去の問い合わせ対応履歴
- 社労士監修の想定Q&A
👉 RAGはQ&A形式を最も得意とします。
② ナレッジ·運用資料
- 就業規則
- 各種規程·細則
- 労務判断基準集
- 休職·復職ガイド
- 労務対応事例集
👉 Q&Aの「根拠」を支える役割です。
③ 労務システムのマニュアル(非常に重要)
意外と軽視されがちですが、これは極めて重要です。
- SmartHRなどの操作マニュアル
- 有給残日数の確認方法
- 勤怠修正の手順
社員はマニュアルを読みません。
RAGが操作手順まで案内できると、自己解決率が一気に上がります。
4. 更新前提で作る(これができないと失敗する)
労務データの最大の特徴は、更新が頻繁に発生することです。
- 法令改正
- 規程改定
- 運用変更
そのため、データセットには必ず以下を持たせます。
- 書類No(ドキュメントID)
- バージョン
- 適用開始日
そして重要なのは、
👉 古いバージョンをRAGに残さないこと
過去データを残すと、RAGは高確率で誤回答します。
5. 表現ゆれ対策は「やりすぎない」
労務分野では、
- 有給/有休/年休
- 残業/時間外労働
などの表現ゆれがあります。
しかし、実務検証では、一般的な労務用語は生成AIが既に理解しているため、
過剰な表現ゆれ辞書の整備は不要でした。
むしろ、
- データの新しさ
- Q&Aの質
- プロンプト設計
の方が圧倒的に重要です。
6. 精度が上がる会社の共通点
労務RAGの導入支援を行う社会保険労務士からは、こんな声が出ています。
就業規則·規程·細則·Q&Aが整備されている会社ほど、
RAGの自動回答比率が70%以上になる
これはつまり、
RAGの精度は、その会社の労務管理レベルの裏返しということです。
逆に言えば、
RAGの回答精度を見ることで、労務管理のアセスメントも可能になります。
7. 労務RAGは「育てるもの」
最後に重要なポイントです。
労務RAGは、
- 一度作って終わり
- 入れた瞬間に完璧
というものではありません。
- Good / Bad フィードバック
- 回答ミスの修正
- Q&Aの追加
- プロンプトの調整
を繰り返し、育てていく仕組みです。
まとめ
AI RAGを労務に活用するうえで最も重要なのは、
AIではなく、データセット設計
です。
- 用途と目的を明確にする
- Q&Aを中心にデータを構成する
- 規程·運用·システムマニュアルを含める
- 更新前提で管理する
これができれば、
労務RAGは「使われないAI」ではなく、
現場で本当に役立つ労務基盤になります。