第5章 RAG導入におけるナレッジ設計とデータ整備
5.1 労務ナレッジの体系化の重要性
AI RAGを労務業務に効果的に適用するためには、労務ナレッジを単に網羅的に収集するのではなく、明確な目的と用途を前提として体系化することが不可欠である。目的や利用者を考慮せずにナレッジを整備した場合、検索精度や回答品質が安定せず、実務での活用が進まない要因となる。
本研究では、労務ナレッジの体系化にあたり、まず用途(誰が利用するか)という観点から整理することが重要であると考える。労務RAGの主な利用者は、①社員、②管理職、③労務担当者の三者に大別され、それぞれが求める情報の粒度や内容は大きく異なる。社員からの問い合わせでは、制度の概要や申請方法、システム操作といった分かりやすさが重視される。一方、管理職からの問い合わせでは、部下対応や判断に関わるルールの解釈や留意点が求められる。さらに、労務担当者からの問い合わせでは、法令や規程に基づく詳細な判断材料や過去事例への参照が重要となる。
次に、目的(何のために使うか)という観点からの整理も欠かせない。労務RAGにおけるナレッジ活用の目的は、大きく二つのパターンに分けられる。一つは、参照すべき書類や根拠を明示した上で、回答案を作成することであり、主に社員向けや管理職向けの問い合わせ対応に該当する。もう一つは、判断を支援することであり、労務担当者や管理職が複雑なケースに対応する際の論点整理や選択肢提示を目的とする。
これらの用途と目的を組み合わせることで、労務ナレッジは「誰に」「何を」「どの深さで」提供すべきかが明確になる。例えば、社員向けの回答案作成を目的とするナレッジでは、Q&A形式や平易な表現が適している。一方、労務担当者向けの判断支援を目的とするナレッジでは、法令条文、通達、過去事例、専門家見解といった情報を構造化して整理する必要がある。
以上のことから、労務ナレッジの体系化は、単なる分類作業ではなく、用途(利用者)と目的(役割)を起点とした設計行為であるといえる。この視点を欠いたナレッジ整備は、RAGの性能を十分に引き出すことができず、運用の形骸化を招く可能性が高い。労務RAGの導入においては、まずナレッジ体系の設計思想を明確にした上で、段階的にデータ整備を進めることが、持続的な活用に向けた前提条件となる。
5.2 学習対象とすべきドキュメントの分類
労務RAGに取り込むドキュメントは、無差別に収集するのではなく、役割と根拠レベルに応じて分類・整理する必要がある。労務業務は制度理解とシステム運用が密接に結びついており、法令や社内規程だけでなく、実際に利用している労務関連システムの仕様や操作手順も労務業務においてAI RAGを有効に活用するためには、単に既存の規程やマニュアルを学習させるだけでは不十分である。生成AIは、労務に関する一般的な制度知識や法令の概要といった「一般教養」に相当する知識については広く学習している一方で、企業固有の運用ルールや最新の制度運用、実務上のつまずきポイントについては十分な情報を持たない。このため、RAGで参照すべき学習対象ドキュメントを適切に定義することが重要となる。
第一に、就業規則や各種規程のみでは判断できない細則が挙げられる。多くの企業では、就業規則に制度の原則が記載されているものの、実際の運用における判断基準や例外対応は、別途細則や運用メモとして管理されているケースが多い。これらの細則は、社員や新任労務担当者が最も迷いやすい領域であり、RAGにおいて優先的に学習させるべき重要なデータセットである。
第二に、生成AIが学習していない、あるいは学習が不十分な労務知識が存在する点である。例えば、残業規制など、労働法改正後の具体的運用方法や、毎年多くの社員がつまずく年末調整の申告要領・記載方法の詳細、労働災害に該当するかの判断などは、一般的な教養知識としては扱われにくい。これらの情報は、企業の実務現場に即した形で整理・定義する必要があり、RAG活用において特に価値の高いデータセットとなる。
第三に、労務担当者によるチェックにおいて差戻しが頻発する申請書類も、重要な学習対象である。差戻しが発生する背景には、社員側の理解不足や記載ミス、添付書類の漏れ等があり、これは制度趣旨や申請ルールが十分に伝わっていないことを示している。差戻し理由や修正ポイントをドキュメント化し、RAGの参照対象とすることで、申請品質の向上と労務担当者の確認工数削減が期待される。
第四に、会社横断的に頻出する社員からの質問が挙げられる。特定部署に限らず繰り返し寄せられる質問は、制度や運用に関する共通の理解ギャップを示しており、RAGにおけるFAQデータセットとして整備する意義が大きい。これにより、社員の自己解決率を高めると同時に、問い合わせ対応の標準化を図ることができる。
第五に、勤怠管理システムや労務管理システムの利用方法などで難解な部分である。これらの管理システムは高機能である一方、操作手順や画面遷移が直感的でない部分も少なくない。システムの公式マニュアルだけでは理解が難しい操作ポイントや、社内特有の設定に基づく運用方法を整理したドキュメントは、RAGにおいて高い実務価値を持つ学習対象となる。
以上のように、労務RAGにおいて重要なのは、生成AIが既に保有している一般的な労務知識を再学習させることではなく、一般教養には含まれない企業固有かつ実務密着型の労務データセットを定義・整備することである。これらのデータセットを体系的に整理しRAGに取り込むことで、労務業務の属人化を抑制し、実務に即した高精度な支援を実現することが可能となる。
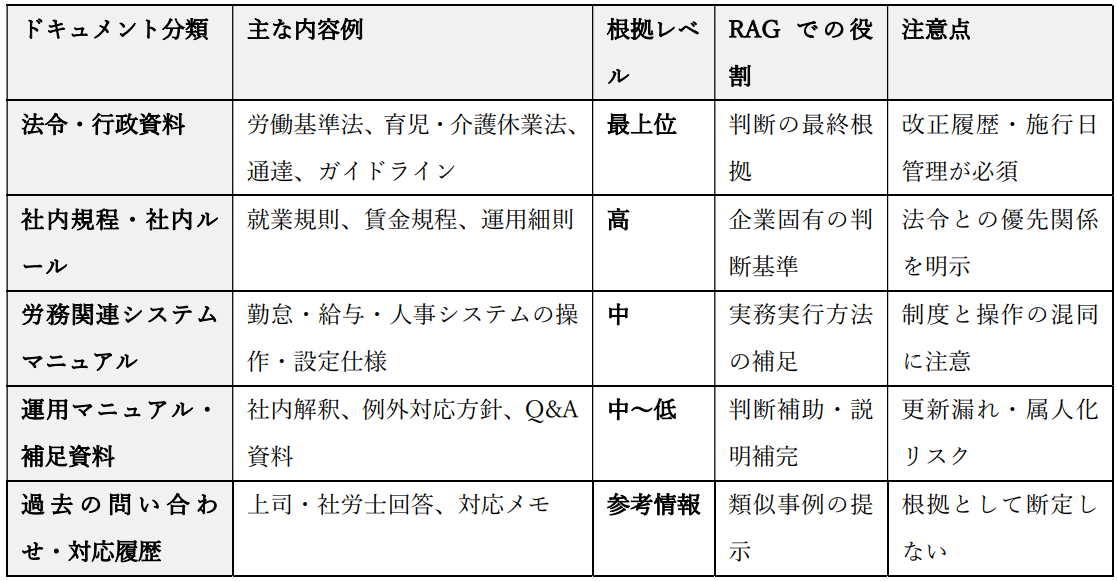
本研究では、労務RAGにおける学習対象ドキュメントを、以下の五つに分類する。
第一に、法令・行政資料である。労働基準法、労働安全衛生法、育児・介護休業法などの関連法令、ならびに行政通達・ガイドラインは、最上位の根拠として扱われるべき情報である。
第二に、社内規程・社内ルール文書である。就業規則、賃金規程、各種運用細則、社内ガイドラインなどは、企業固有の判断基準として重要な位置を占める。
第三に、労務関連システムのマニュアル・操作仕様書である。勤怠管理システム、給与計算システム、人事管理システムなどの利用方法や設定仕様は、実務における問い合わせ内容と密接に関連している。社員や管理職からの質問の多くは、「制度として可能かどうか」だけでなく、「システム上どのように操作すればよいか」という点に集中するため、これらのマニュアルをRAGの検索対象に含めることは不可欠である。
第四に、運用マニュアル・補足資料である。法令や社内規程をどのように実務へ落とし込んでいるかを示す内部資料や、例外対応の考え方をまとめた文書は、判断を補助するナレッジとして価値を持つ。
第五に、過去の問い合わせ・対応履歴である。労務担当者が上司や社労士に確認した結果を含むこれらの情報は、実務判断の蓄積として有用であるが、法令や規程と同等の根拠として扱わないよう、位置づけを明確にした上で管理する必要がある。
このように、労務RAGでは「制度ナレッジ」と「システム運用ナレッジ」を分離しつつ統合的に扱う設計が重要となる。制度として正しい内容であっても、システム上の制約により実行できないケースも存在するため、両者を併せて参照できることが、実務に即した回答生成につながる。
加えて、労務関連システムの利用に関しては、多くの社員が公式マニュアルを参照しないという実態も考慮する必要がある。例えば、「自分の有給休暇は何日残っているか」といった、制度やシステム上は容易に確認可能な内容についても、社員から労務担当者へ直接問い合わせが寄せられるケースは少なくない。
このような問い合わせは、社員の理解不足というよりも、「どこを、どのように確認すればよいか分からない」ことに起因している場合が多い。労務関連システムでは、有給残日数や申請状況を画面上で確認できるにもかかわらず、操作手順が直感的でない場合や、必要な画面への導線が分かりにくいことが、問い合わせ発生の要因となっている。
この点において、RAGを活用し、「システム上での確認方法そのもの」を回答として提示できることは大きな意義を持つ。RAGが、該当する画面の確認手順や操作ポイントを案内することで、社員は労務担当者に問い合わせることなく、自身で情報を確認・解決できるようになる。これは、単なる制度説明ではなく、システム利用を前提とした実務的支援であり、労務担当者の対応工数削減と社員の自己解決率向上の双方に寄与する。
以上のことから、労務RAGにおける学習対象としては、制度や規程そのものに加え、社員がつまずきやすい労務システムの利用方法や確認手順を整理したデータセットを含めることが重要である。
5.3 Q&A形式とドキュメント形式の使い分け
AI RAGの検索精度および回答品質を高めるためには、学習対象とするドキュメントの形式を適切に使い分けることが重要である。労務業務においては、Q&A形式のデータと、規程・ナレッジ文書・マニュアル等のドキュメント形式のデータが混在しており、それぞれが果たす役割は異なる。
本研究において当社で実施した検証結果によれば、RAGのベクトルデータベースにおける検索精度は、第1優先としてQ&A形式のデータ、第2優先としてナレッジ文書やマニュアルを参照する構成が最も有効であることが確認された。すなわち、検索時にQ&A形式のデータを優先的にヒットさせ、その補完情報としてナレッジ文書やマニュアルを参照する設計が、回答の一貫性および実務適合性の向上に寄与する。
Q&A形式のデータは、社員や労務担当者が実際に使用する自然文に近い形で整理されており、質問意図との一致度が高い。そのため、検索クエリとの意味的距離が短く、RAGによる初期検索段階において高い精度を発揮する。一方で、Q&A単体では背景や制度全体の文脈が不足する場合があり、誤解や例外対応への配慮が不十分となる可能性がある。
これに対して、ナレッジ文書やマニュアルは、制度の全体像や運用ルール、システム操作手順を体系的に整理した情報源であり、Q&Aで示された結論や回答を補強する役割を果たす。RAGがこれらのドキュメントを第2優先で参照することで、回答の根拠提示や具体的な運用手順の説明が可能となり、実務上の再質問や誤運用の抑制につながる。
さらに当社の検証では、RAGの検索精度および回答品質は、汎用的なAIプロンプトを用いるだけでは十分に向上せず、労務業務に特化したプロンプト設計を行うことが不可欠であることも確認された。労務領域では、「法令」「社内規程」「運用」「例外」といった観点を意識的に区別する必要があり、これらを前提とした指示文(プロンプト)を設計することで、検索結果の選別精度および回答構造の安定性が大きく向上する。
以上を踏まえると、労務RAGにおける効果的な設計としては、Q&A形式のデータを検索の起点とし、その背後にナレッジ文書およびマニュアルを配置する多層構造に加え、労務業務に最適化されたAIプロンプトを組み合わせることが重要である。この構成により、検索精度と説明責任の両立が可能となり、「迅速に理解できる回答」と「根拠に基づく説明」を同時に実現することができる。
このようなQ&A形式、ドキュメント形式、プロンプト設計の役割分担は、労務RAGの精度向上のみならず、ナレッジ整備および運用設計の優先順位を明確にする指針としても有効であり、RAG導入初期における実務的な設計指針となる。
5.4 メタデータ設計と検索精度への影響
AI RAGの検索精度および回答の信頼性を担保する上で、メタデータ設計は極めて重要な要素である。特に労務業務においては、参照する情報の正確性や最新性が求められるため、単に文書を学習させるだけでは不十分であり、更新を前提としたデータ管理設計が不可欠となる。
本研究における当社の労務データセットに関する調査・検証の結果、RAGで扱うデータの多くが、社内規程、運用ガイド、申請書式、法令・通達など、不定期で更新が必要となるデータセットで構成されていることが確認された。これらのデータは、制度改定や法令変更、社内運用の見直しに伴い内容が変更されるため、古い情報を参照した場合には誤回答や誤運用につながるリスクが高い。
このような特性を踏まえると、労務RAGにおけるメタデータ設計では、詳細で複雑な属性情報を付与することよりも、更新管理を容易にし、常に最新データを参照できる仕組みを構築することが重要となる。本研究では、その実践的手法として、各データセットに書類No(ドキュメントID)およびバージョン番号を付与し、元データを一元管理する方法が有効であることを確認した。
具体的には、就業規則や細則、運用ガイド等の各ドキュメントに一意の書類Noを設定し、改訂のたびにバージョン番号を更新する。RAG上では、この書類Noをキーとしてデータを管理し、最新版のみを検索・参照対象とする更新機能を実装することで、古い情報が検索結果に混在することを防止できる。
なお、検証の結果、過去バージョンのデータをRAG内に残すことは、検索精度および回答の安定性の観点から有効ではないことも明らかとなった。古いバージョンが残存している場合、検索時に意味的に近いが内容が異なる文書がヒットし、誤った根拠提示や回答の揺らぎを生じさせる要因となる。このため、RAGにおいては履歴管理を主目的とせず、常に最新かつ正とされたデータのみを参照対象とする設計が望ましい。
以上のことから、労務RAGにおけるメタデータ設計の要点は、検索精度向上を目的とした属性の付与ではなく、更新管理と参照統制を中心としたシンプルな設計にあるといえる。書類Noとバージョン管理を基軸としたメタデータ設計により、RAGは常に最新の制度・運用情報に基づいた回答を生成でき、労務業務に求められる正確性と説明責任を高い水準で両立することが可能となる。
5.5 ナレッジ正規化と表現ゆれ対策
RAGを用いた業務支援においては、一般にナレッジの正規化や表現ゆれ対策が検索精度および回答品質に大きな影響を与えるとされている。特に専門用語や略語、俗称が混在する業務領域では、同義語辞書の整備や表現統一が重要な設計要素として論じられることが多い。
一方で、本研究において当社が実施した労務分野の検証では、労務用語に関する表現ゆれがRAGの回答精度に与える影響は限定的であることが確認された。具体的には、労務分野で頻出する約300語の用語を対象に、正規表現と表現ゆれを含むデータセットを用いて検証を行った結果、現行の生成AIは、これらの用語を一般常識レベルの知識として既に広く学習しており、検索および回答の精度に顕著な差は生じなかった。
この結果は、労務分野における多くの基本用語や表現が、生成AIにとって新規性の高い専門知識ではなく、社会制度や一般的業務知識として学習済みであることを示唆している。したがって、「有給」「年休」「有休」や「残業」「時間外労働」といった代表的な表現ゆれについては、RAGの検索段階や回答生成段階で自然に吸収され、精度低下の要因とはなりにくい。
以上の検証結果を踏まえると、労務RAGにおいては、用語正規化や表現ゆれ対策に過度な工数をかける必要はないと判断できる。複雑な同義語辞書の構築や、細かな表記統一ルールの策定は、コストに見合う効果を生まない可能性が高い。
むしろ、労務RAGの精度向上において優先すべきは、第5.2節および第5.3節で論じたような、学習対象ドキュメントの選定、更新管理、Q&A形式の活用、プロンプト設計といった上流設計である。これらの要素に比べると、表現ゆれ対策は相対的に影響度が低い位置づけとなる。
ただし、本節の結論は、すべての労務ナレッジに対して正規化が不要であることを意味するものではない。社内独自の略称や、特定企業内でのみ通用する用語、システム固有の項目名などについては、必要に応じて補足的な正規化を行うことが望ましい。重要なのは、表現ゆれ対策を目的化せず、影響度に応じて最小限に設計する姿勢である。
以上のことから、労務分野におけるナレッジ正規化は、RAG設計全体の中で優先度を適切に見極め、必要最小限にとどめることが、実務的かつ合理的なアプローチであるといえる。
5.6 法令・社内規程の更新管理
労務業務においては、法改正や社内規程の変更が頻繁に発生するため、ナレッジの更新管理が不可欠である。RAG導入後も、元となるナレッジが最新でなければ、誤った回答を生成するリスクは避けられない。
更新管理においては、文書の改訂履歴や適用開始日を明確に管理し、古い情報が参照されない仕組みを整える必要がある。また、法改正に伴う影響範囲を整理し、関連するナレッジを一括で更新できる体制を構築することが望ましい。
このように、ナレッジを「一度作って終わり」にするのではなく、継続的にメンテナンスする前提で設計することが、労務RAGを実務で定着させる鍵となる。